Artificial intelligence
Last Updated: Feb 15, 2024
Reward
Consider the following reinforcement learning model of the agent-environment interface (see also MS&E 388 lecture notes). There exist a set of actions \(\mathcal{A}\) and observations \(\mathcal{O}\). At each time step t, the agent chooses an action \(A_t \in \mathcal{A}\), observes \(O_{t+1} \in \mathcal{O}\) and receives reward \(R_{t+1} = r(X_t, A_t, O_{t+1})\) for \(X_t\) an internal state. The interal state also generates \(A_t \sim \pi(\cdot \mid X_t)\) and updates with \(X_{t+1} \sim \nu(\cdot \mid X_t, A_t, O_{t+1})\).
Although this representation allows reward to depend on agent state, it does not give particular insight into what \(X_t\) itself should look like. One knows from experience that real-world intelligent agents maintain very sophisticated internal models of the world, are able to identify and integrate relevant information from high-dimensional signals into these world models, predict the possible future consequences of actions, and select actions which the agent believes will further the agent’s own goals. Environmental feedback from an agents actions is by no means instantaneous, and very intelligent agents are capable to some degree of predicting the long term consequences of actions. Agents are also highly capable of learning from nature or from other agents through purely passive observation or by imitation. Real world feedback is rich, and real world control is complex.
Both feedback and control are hierarchical. Real-world intelligent agents fluidly decompose tasks into solvable subproblems, and are able to improvise if obstacles are encountered. For example, going to the grocery store to purchase milk requires a human to be able to:
- determine where one is relative to the grocery store
- walk
- navigate a course to the grocery store, avoiding obstacles and rerouting if environmental hazards arise
- understand whether the grocery store is open, and if so, how to enter it
- navigate the social environment of the grocery store
- navigate the physical environment of the grocery store
- identify what kind of milk is needed and explore the grocey store until the milk is found
- exert fine motor control to open the refrigerator door, pick up the milk, and carry it
- locate the grocery checkouts
- understand the social concepts of waiting in line and paying for goods with money
- assess whether the appropriate price is being charged for the milk, and complain if not
- understand if one’s method of payment is not working, and determine a solution
- understand that one has successfully purchased the milk, and that it is socially appropriate to leave
- locate the exit and walk out of the grocery store
and the solution of many other problems. Humans routinely do all these tasks, often while distracted by more interesting thoughts.
Many heterogeneous types of “reward” are involved in the above description. Each subproblem has a different notion of success. Yet humans seamlessly coordinate the entire sequence in order to purchase milk, which in most cases is yet another subproblem for a higher-level objective. Negative rewards also occur on many different levels, and agents are able to accurately assess and respond to these signals differently. Stubbing a toe while walking and discovering that the grocery store is closed are both unpleasant, but require very different responses. Even if the reward metaphor is useful for understanding the behavior of actually intelligent agents, it must be admitted that being human does not feel like maximizing an observable scalar quantity by carefully selecting actions one at a time.
Yann LeCun offers an interesting vision of what the internal state of intelligent agents might require in A path towards autonomous machine intelligence version 0.9.2, 2022-06-07. Yann has been active on Twitter in his criticism that large language models cannot truly reason because they lack a world model capable of predicting the likely consequences of actions. He has also remarked that human babies are able to learn a lot about the world sheerly through visual observation including that the world is three dimensional, the world is made of different kinds of objects that have permanance, that some objects move predictably, and that cause and effect relationships exist between objects. An intelligent machine would be able to draw similar conclusions simply by observing a video feed, before any control loop or reward enters the picture.
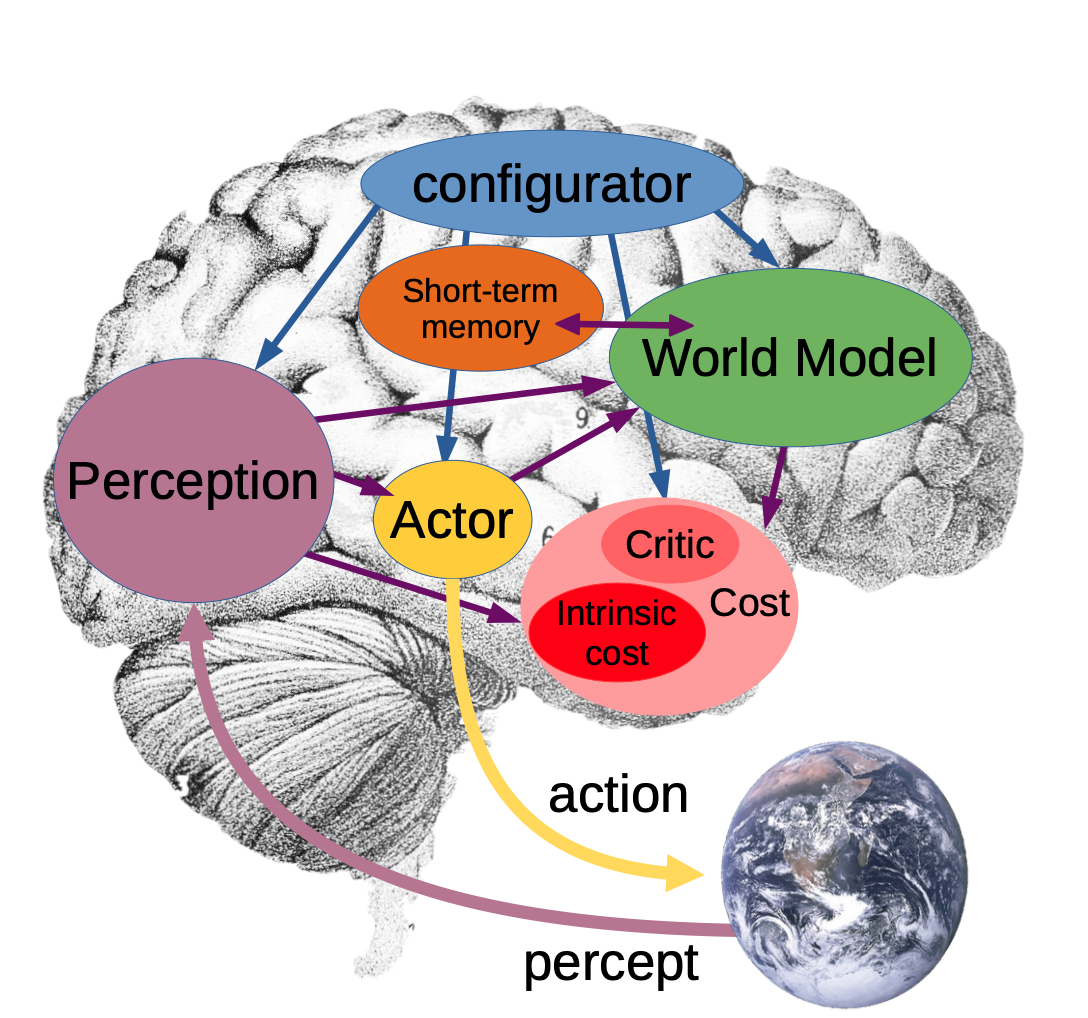
- LeCun talk Sep 2023: From machine learning to autonomous intelligence
All known natural intelligences are able to decide between different possible actions. Actions are not chosen randomly, and usually correspond to a choice that furthers the interest that the agent has in staying alive or reproducing, or another goal. The existence of this choice in the presence of feedback from an external world that is indifferent or adversarial, combined with our own intuitive experience of being human, is a strong suggestion that intelligence depends on being able to model the world, predict the possible consequences of several actions, and choose the action best suited for the achievement of a particular goal. Autoregressive models predicting the next token from a sequence of previous tokens, as LeCun notes, do not do this.
See also the soft robotics note.
Hierarchical Planning
Currently unsolved: learning how to construct hierarchical plans from data.